High-Level Strategy
Why run local? It comes down to three things: Privacy, Control, and Cost. When you run AI locally, your data never leaves your building. You pay for hardware once, not monthly. And you can run uncensored, specialized models that big cloud providers won't offer.
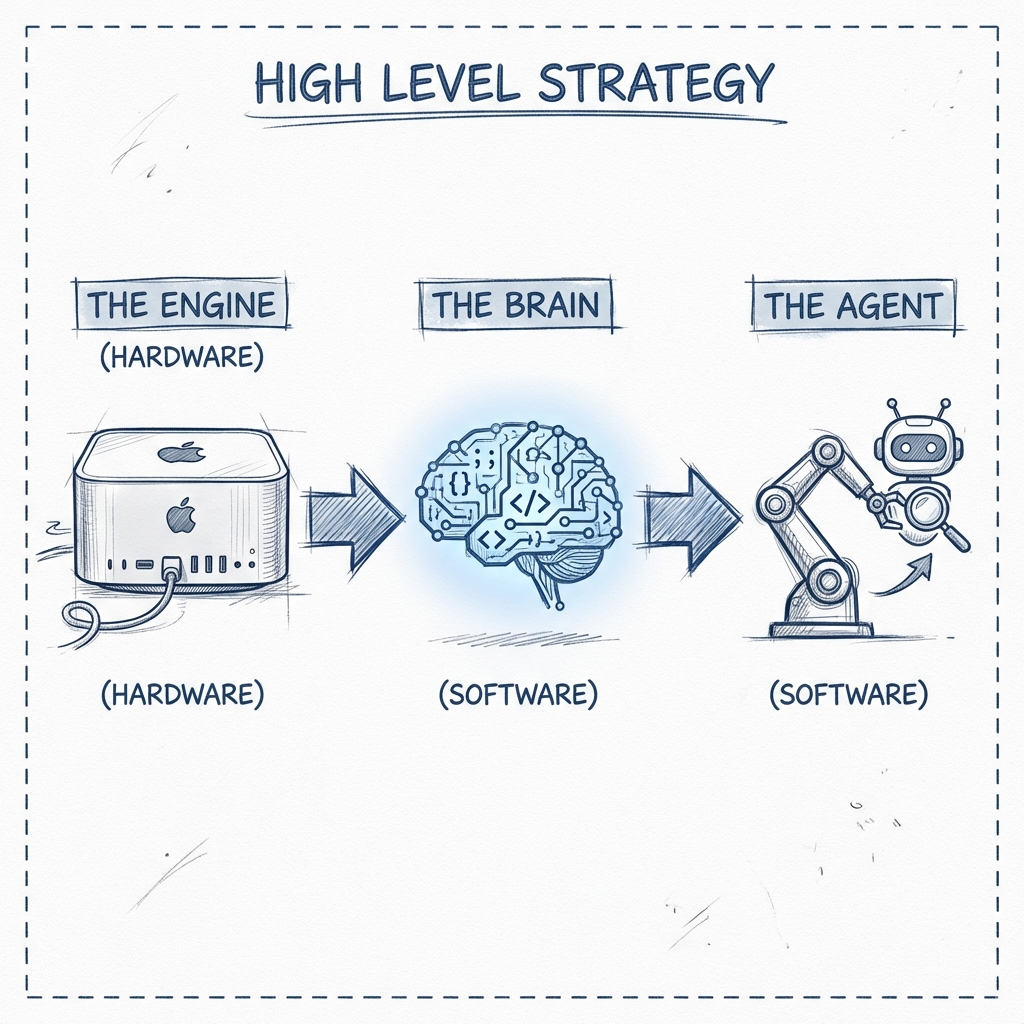
1. The Engine (Hardware)
Deep learning eats RAM for breakfast. We need high-speed, unified memory.
- Mac Studio (M-Series) is King
- High RAM > High GPU Power
- One-time investment
2. The Brains (Models)
Open source is now neck-and-neck with closed models.
- Reasoning: DeepSeek R1
- Coding: Qwen 2.5 Coder
- Images: Flux / Stable Diffusion
3. The Agent (OpenClaw)
Models just talk. Agents do.
- Independent Worker
- Can browse web & use tools
- Connects to your local models
